
Exploring the World of Multimodal AI: Comprehensive Insights and Applications
Exploring the World of Multimodal AI: Comprehensive Insights and Applications
Key Takeaways
- Multimodal AI uses multiple input sources (text, images, audio, sensors) to achieve better results and more advanced applications.
- Multimodal AI is more knowledgeable and can associate different inputs to provide enhanced outcomes.
- Examples of multimodal AI models include Google Gemini, OpenAI’s GPT-4V, Runway Gen-2, and Meta ImageBind.
Early AI models impressed based on their ability to interpret text prompts, but multimodal AI is capable of so much more. As existing models expand to accept more input modalities, AI tools are only going to get more advanced.
What Does “Multimodal” Mean?
The word “multimodal” literally refers to the use of multiple modes, and in the context of AI, that means the use of different input sources for both training and to get more informed results. Chatbots that took the world by storm in 2023 were only capable of a single input mode, which was text.
Multimodal AI is capable of accepting two or more input methods. This applies both when training the model and when interacting with the model. For example, you could train a model to associate certain pictures with certain sounds using both image and audio datasets. At the same time, you could ask a model to combine a text description and an audio file in order to generate an image that represents both.
Potential input modes include text, images, audio, or information from sensors like temperature, pressure, depth, and so on. These modes can be prioritized within the model, weighting the results based on the intended result.
Multimodal models are an evolution of the unimodal models that saw an explosion in popularity during 2023. Unimodal models are only capable of taking a prompt from a single input (like text). A multimodal model can combine multiple inputs like a description, an image, and an audio file to provide more advanced results.
How Is Multimodal AI Better Than Regular AI?
Multimodal AI is the logical evolution of current AI models that allows for more “knowledgeable” models. The applications for these models are far broader, both in terms of consumer use, machine learning, and industry-specific implementation.
Let’s say you wanted to create a new image based on a photo you had taken. You could feed the photo to an AI and describe the changes you wanted to see. You could also train a model to associate sounds with a particular type of image or to draw associations like temperature. These types of models would have “better” results even if you’re only interacting with them over text.
Other examples include captioning videos using both audio and video to sync text to what’s happening on the screen or better information gathering using charts and infographics to bolster results. Of course, you should always maintain a healthy level of skepticism when conversing with a chatbot .
Multimodal AI is gradually making its way into everyday technology. Mobile assistants could be greatly improved with the use of multimodal models since the assistant will have more data points and added context to make better assumptions. Your smartphone already has cameras, microphones, light and depth sensors, a gyroscope and accelerometer, geolocation services, and an internet connection. All of this could be useful to an assistant in the right context.
The implications for industry are vast. Imagine training a model to perform some type of maintenance task using several inputs so that it can make better judgments. Is a component getting hot? Does the component look worn? Is it louder than it should be? This can be combined with basic information like how old the component is and its average lifespan, then inputs can be weighted to come to reasonable conclusions.
Some Examples of Multimodal AI
Google Gemini is perhaps one of the best-known examples of multimodal AI. The model hasn’t been without controversy, with a video demonstrating the model released in late 2023 branded “fake” by detractors. Google admitted that the video was edited, that the results were based on still images and didn’t take place in real-time, and that prompts were provided by text rather than spoken aloud.

Developers can already get started using Gemini today simply by applying for an API key in Google AI Studio. The service has been launched at a “free for everyone” tier with a limit of up to 60 queries per minute. You’ll need a firm understanding of Python to set up the service (here’s a good tutorial to get started).
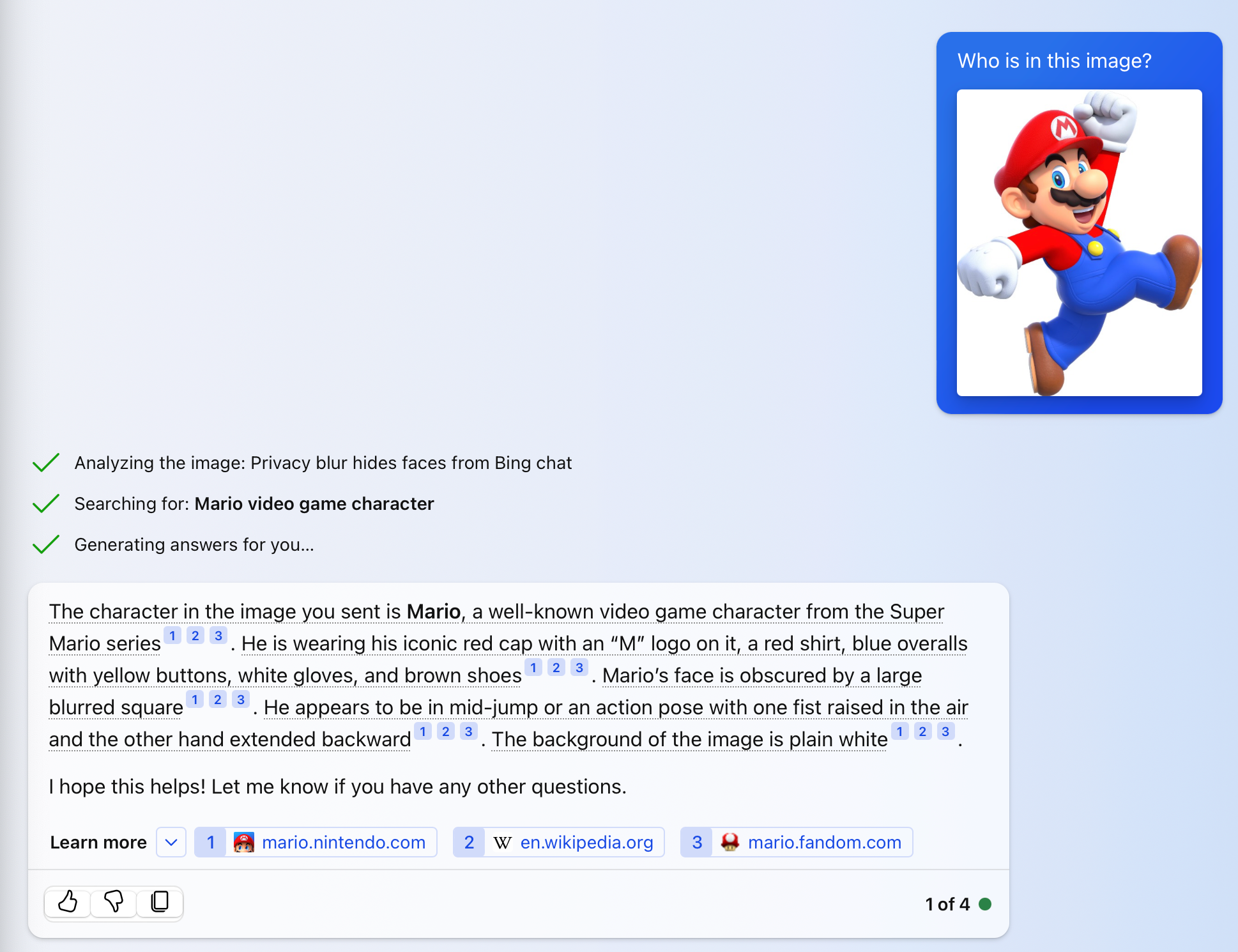
That said, Gemini is still a promising multimodal AI model that has been trained on audio, images, videos, code, and text in different languages. It goes head to head with OpenAI’s GPT-4 , which can accept prompts of both text and images. Also known as GPT-4V (with the V standing for vision), the model is available to ChatGPT Plus users via the OpenAI website , mobile apps, and API.
You can use GPT-4V for free via Bing Chat to upload images or snap photos from your device’s camera or webcam. Just click on the image icon in the “Ask me anything…” box to attach an image to your query.
Other multimodal models include Runway Gen-2 , a model that produces videos based on text prompts, images, and existing videos. At present the results look very AI-generated, but as a proof of concept, it’s still an interesting tool to play with.
Meta ImageBind is another multimodal model that accepts text, images, and audio plus heat maps, depth information, and inertia. It’s worth checking out the examples on the ImageBind website to see some of the more interesting results (like how audio of pouring water and a photo of apples can be combined into an image of apples being washed in a sink).
The adoption of multimodal AI models is bad news for anyone who is already sick of hearing all about the technology, and it’s bound to keep companies like OpenAI in the news for a little while longer. The real story though is how companies like Apple, Google, Samsung and other big players will bring this technology home and into the palms of consumers.
Ultimately, you don’t have to know that you’re interacting with another AI buzzword to reap the benefits. And outside of consumer electronics, the potential in fields like medical research, drug development, disease prevention, engineering, and so on might have the greatest impact of all.
Also read:
- [Updated] Techniques to Slow Down Online Video Playback (49 Chars) for 2024
- 2024 Approved MovieMakerMag Extreme Review – Complete Take on AndroVid Editor
- 9 Essential Strategies: Enhancing Wellness with ChatGPT
- 9 Ways ChatGPT Can Make Your Life Easier
- 如何高效地为DVD制作或转录字幕,完美观看体验
- A Closer Examination of Elon Musk’s Cutting-Edge Technology - The Reality of TruthGPT
- AI Confrontation: Assessing Which Is Supreme - ChatGPT, Bing by Microsoft or Google's Bard?
- AI-Driven Prompt Development: Industry Standing & Career Stability?
- Best 3 Honor Magic5 Ultimate Emulator for Mac to Run Your Wanted Android Apps | Dr.fone
- ChatGPT as a Creative Writing Tool: Explore Six Tactics to Improve Your Craft.
- Exciting Times for Everyone: GPT-4 Is Now Free; Plus Still Shines with 6 Benefits
- Low-Cost Android Calls Highest Ranking Options for 2024
- New 2024 Approved How to Get Zoom on TV Easy Solutions
- Resolving Non-Loading Errors in Urban Planning Simulator Skyline Builders 2
- Simple Guides for Recording Vimeo Content
- SnapStream App Rating Analysis
- The 6 Worst ChatGPT Extensions You Should Avoid Now
- Title: Exploring the World of Multimodal AI: Comprehensive Insights and Applications
- Author: Larry
- Created at : 2024-12-23 11:19:08
- Updated at : 2024-12-27 23:37:54
- Link: https://tech-hub.techidaily.com/exploring-the-world-of-multimodal-ai-comprehensive-insights-and-applications/
- License: This work is licensed under CC BY-NC-SA 4.0.